Vadnica za HBase: Uvod v HBase in študija primera na Facebooku
Ta blog o vadnicah HBase vas seznani s tem, kaj je HBase in njegovimi lastnostmi. Obsega tudi študijo primera Facebook Messenger, da bi razumeli prednosti HBase.

Ta blog o vadnicah HBase vas seznani s tem, kaj je HBase in njegovimi lastnostmi. Obsega tudi študijo primera Facebook Messenger, da bi razumeli prednosti HBase.
Ta spletni dnevnik je vodnik o tem, kako namestiti Puppet Master in Puppet Agent. Vključuje tudi primer namestitve Apache Tomcat z uporabo modula Puppet Tomcat.
Ta spletni dnevnik je vodnik po korakih za namestitev Apache Pig v okolju Linux. Namestili bomo Apache Pig 0.16.0 in ga zagnali v različnih načinih.
Ta spletni dnevnik o arhitekturi HBase pojasnjuje model HBase podatkov in daje vpogled v arhitekturo HBase. Pojasnjuje tudi različne mehanizme v HBase.
Ta blog o vajah Hive vam daje poglobljeno znanje o arhitekturi panja in podatkovnem modelu panja. Pojasnjuje tudi študijo primera NASA o panju Apache.
Ta spletni dnevnik Spark Streaming vam bo predstavil Spark Streaming, njegove značilnosti in komponente. Vključuje projekt Sentiment Analysis z uporabo Twitterja.
Ta spletni dnevnik Spark MLlib vam bo predstavil knjižnico strojnega učenja Apache Spark. Vključuje projekt sistema za priporočanje filmov z uporabo Spark MLlib.
Ta blog Vadnice za GraphX vas bo seznanil z Apache Spark GraphX, njegovimi funkcijami in komponentami, vključno s projektom analize podatkov o letih.
V tem blogu z vadnicami za Apache Flume so razložene osnove Apache Flume in njegove značilnosti. Predstavil bo tudi pretakanje Twitterja z uporabo Apache Flume.
Vadnica za Apache Sqoop: Sqoop je orodje za prenos podatkov med Hadoop in relacijskimi bazami podatkov. Ta spletni dnevnik pokriva uvoz in izvoz podjetja Sooop iz MySQL.
Vadnica za Apache Oozie: Oozie je sistem za načrtovanje delovnega toka za upravljanje opravil Hadoop. To je razširljiv, zanesljiv in razširljiv sistem.
Aplikacije Big Data revolucionirajo organizacije in jim pomagajo do bolj informativnih poslovnih odločitev z analizo velike količine podatkov.
Apache Spark je prevzel svet velikih podatkov in analitike, Python pa je eden najbolj dostopnih programskih jezikov, ki se danes uporabljajo v industriji. Torej, v tem blogu bomo izvedeli več o Pysparku (iskri s pythonom), da dobimo najboljše iz obeh svetov.
Ta spletni dnevnik se osredotoča na Apache Hadoop YARN, ki je bil uveden v različici Hadoop 2.0 za upravljanje virov in razporejanje delovnih mest. Pojasnjuje arhitekturo YARN z njenimi komponentami in nalogami, ki jih opravlja vsak od njih. Opisuje oddajo vloge in potek dela v Apache Hadoop YARN.
V tem blogu o vajah za PySpark boste izvedeli več o API-ju PSpark, ki se uporablja za delo z Apache Spark z uporabo programskega jezika Python.
V tem blogu vadnic PySpark Dataframe boste z več primeri spoznali transformacije in dejanja v Apache Spark.
Ta spletni dnevnik Edureka v vadnici Cloudera Hadoop vam bo dal popoln vpogled v različne komponente Cloudere, kot so Cloudera Manager, Parcels, Hue itd.
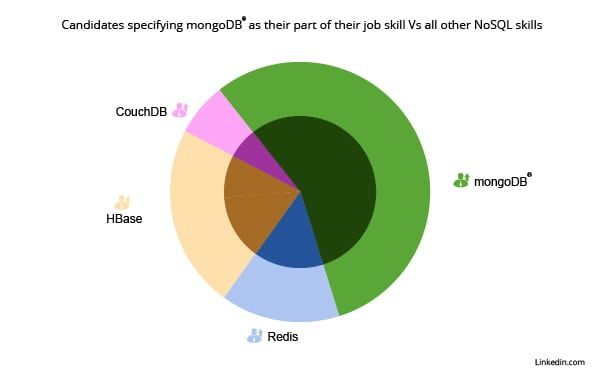
Ta objava opisuje povečano povpraševanje po znanjih Hadoop in NoSQL na področju IT in drugih področij. preberite, kako bodo pomagale veščine Hadoop in NoSQL
Ta blog razpravlja o prednostih izvajanja Hadoopa, pobudah Hadoop, Hadoopu v majhnih in velikih organizacijah ter koristih kariere Hadoop treninga.
Hadoop je postal vroča veščina, ki jo je treba pridobiti v IT vezju, število profilov učencev Hadoop pa se iz dneva v dan drastično povečuje.